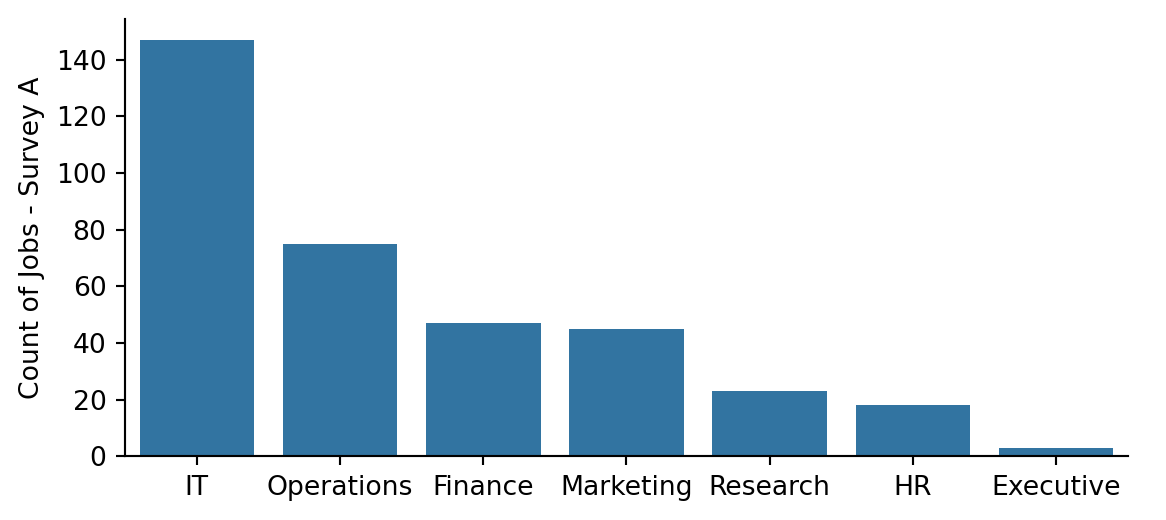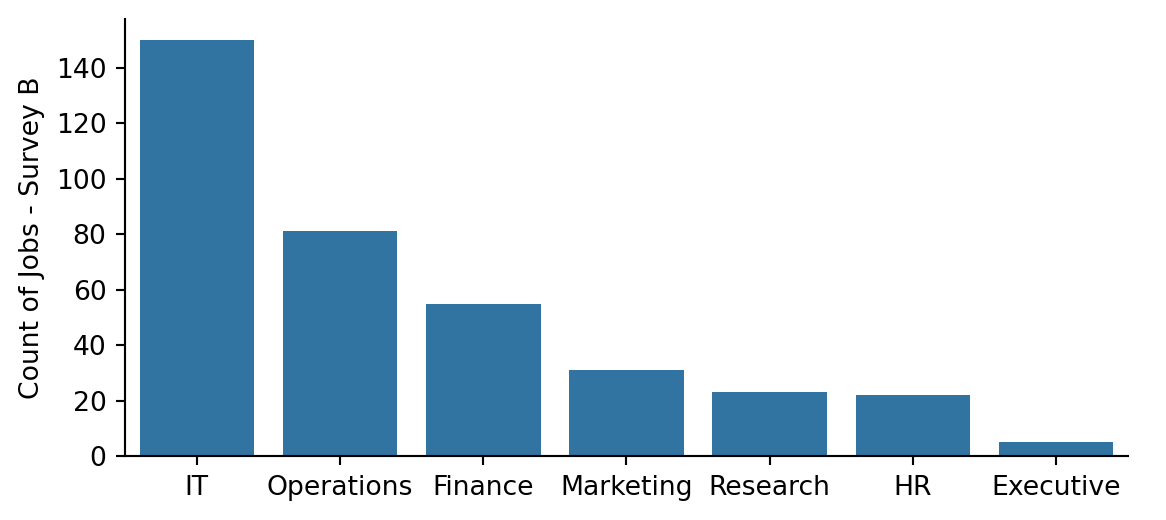HR professionals often go through the process of matching jobs from various compensation surveys to determine the pay ranges for related job codes. However, this is often a manual and lengthy process involving a lot of human judgement. One way to that HR can use Python to save time in this process is by building a kth-nearest neighbor model with sci-kit learn to “fuzzy-match” jobs.
So let’s get started by importing all the relevant modules.
Code
import osimport sysimport pandas as pdimport difflibimport regex as refrom ftfy import fix_textfrom sklearn.neighbors import NearestNeighborsfrom sklearn.feature_extraction.text import TfidfVectorizerimport numpy as npfrom scipy.sparse import csr_matriximport sparse_dot_topn.sparse_dot_topn as ctimport timefrom great_tables import GT, exibblefrom sklearn.utils import shuffleimport seaborn as snsimport warningspd.set_option('display.max_columns', None) #show all columns when using head()pd.options.display.float_format ='{:.2f}'.formatnp.set_printoptions(suppress=True) # suppres scientific notationwarnings.filterwarnings("ignore")
Next, we will load the CSV files from each survey. We need to encode the files in the default Microsoft format (code page 1252). Let’s take a peek at the first few rows of those files too.
Job Summary: Provides analysis of quantitative and
Operations
11423
Product Marketing Analyst II
Job Summary: Assists in the development of marketi
HR
ADS16111740
Mergers & Acquisitions Analyst I
Compiles and analyzes data required for merger, ac
Finance
Now let’s take another look at the number of jobs per job family for each survey.
Code
g = sns.catplot(x="Family", data=survey_a, kind="count", order=survey_a.Family.value_counts().index, height=3, aspect=2)g.set_axis_labels("", "Count of Jobs - Survey A")survey_a.describe()
Job Code
Job Title
Description
Family
count
358
358
358
358
unique
345
355
358
7
top
11175
Mechanical Engineer II
Assists in maintaining financial records and e...
IT
freq
3
2
1
147
Code
g2 = sns.catplot(x="Family", data=survey_b, kind="count", order=survey_b.Family.value_counts().index, height=3, aspect=2)g2.set_axis_labels("", "Count of Jobs - Survey B")survey_b.describe()
Job Code
Job Title
Description
Family
count
367
367
367
367
unique
352
364
367
7
top
2111
Cost Accountant IV
Provides administrative support to for one or ...
IT
freq
3
2
1
150
Ok they both look very similar, so I see no reason why not to proceed, first by creating a column to join the data on. Then comes the good part. Here we set the model parameters, removing all special characters and setting the whole string to the same case. We’ll try to match every third character (“n=3”) so as to maximize the potential matches.
Code
survey_a['match_column'] = survey_a['Job Title'] +'_'+ survey_a['Description'] #columns to join onsurvey_b['match_column'] = survey_b['Job Title'] +'_'+ survey_b['Description']#model def ngrams(string, n=3): string =str(string) string = fix_text(string) # fix text string = string.encode("ascii", errors="ignore").decode() #remove non ascii chars string = string.lower() chars_to_remove = [")","(",".","|","[","]","{","}","'",":","-"] rx ='['+ re.escape(''.join(chars_to_remove)) +']' string = re.sub(rx, '', string) string = string.replace('&', 'and') string = string.replace(',', ' ') string = string.replace('-', ' ') string = string.replace('_', ' ') string = string.title() # normalise case - capital at start of each word string = re.sub(' +',' ',string).strip() # get rid of multiple spaces and replace with a single string =' '+ string +' '# pad names for ngrams... string = re.sub(r'[,-./]|\sBD',r'', string) ngrams =zip(*[string[i:] for i inrange(n)])return [''.join(ngram) for ngram in ngrams]#convert to unicodeunique_a = survey_a['match_column'].unique().astype('U')unique_b = survey_b['match_column'].unique().astype('U')
This next step vectorizes the data using a term-frequency / inverse document frequency method common to vector databases. Yes, this is effectively the same method that you would use to build a vector database common to generative AI applications.
Code
### Build vectorizervectorizer = TfidfVectorizer(min_df=1, analyzer=ngrams)### Nearest neighbors on matching columntfidf = vectorizer.fit_transform(unique_a.astype('U'))nbrs = NearestNeighbors(n_neighbors=1, n_jobs=-1).fit(tfidf)### Matching query, assigning numerical values to the distances between each row in the match columnsdef getNearestN(query): queryTFIDF_ = vectorizer.transform(query) distances, indices = nbrs.kneighbors(queryTFIDF_)return distances, indices### Getting nearest Ndistances, indices = getNearestN(unique_b)### convert back to a listunique_b =list(unique_b)### find matchesmatches = []for i,j inenumerate(indices): temp = [round(distances[i][0],2), unique_a[j][0],unique_b[i]] matches.append(temp)### building data framematches = pd.DataFrame(matches) matches = matches.rename({0: "match_confidence",1: "match_column_a",2:"match_column_b"}, axis=1)### bring survey a data back inmatches_a = survey_a.merge(matches, left_on='match_column', right_on='match_column_a', how='left', suffixes=('','_a'))### merge back with survey b datamatches_all = pd.merge(matches_a, survey_b, left_on='match_column_b', right_on='match_column', how='left', suffixes=('','_b'))### clean upmatches_all.columns = matches_all.columns.str.replace(' ', '_') #replaces spaces with underscoresmatches_all.columns =map(str.lower, matches_all.columns) #make all column headers lowercasematches_all = matches_all.dropna(subset=['match_confidence']) #drop NAsbest_match_score = matches_all### flip signs so that higher confidence is better and roundbest_match_score.loc[:, 'match_confidence'] =round( (best_match_score.loc[:, 'match_confidence']-min(best_match_score.loc[:, 'match_confidence']))/ (max(best_match_score.loc[:, 'match_confidence'])-min(best_match_score.loc[:, 'match_confidence'])) ,3)#(x-min(x))/(max(x)-min(x))### save as csv and read back inbest_match_score.to_csv(obj_path +'best_match_score.csv', index=False)preview_c = pd.read_csv(obj_path +'best_match_score.csv', encoding='cp1252')
Hooray. Now we’ve built the model. Let’s sort and pick out the final columns we need before we preview a random sample of the final data.
Job Summary: Assists in the development and implementation of processes and programs designed to maximize employee productivity, performance, and enga . . .
11364
Sr. Associate Consultant
Job Summary: Conducts research and analysis in support of more senior consultants. Job Duties: Identifies sources of information, conducts research, c . . .
0.663
3160_2
IT Database Administrator II
Job Summary: Administers and controls the activities related to data planning and development, and the establishment of policies and procedures pertai . . .
464
IT Database Administrator I
Job Summary: Administers and controls the activities related to data planning and development, and the establishment of policies and procedures pertai . . .
0.051
2102_2
Research Scientist I
Job Summary: Plans, organizes, and performs scientific research projects in a particular scientific or academic field. Job Duties: Creates and conduct . . .
2111_2
Research Scientist V
Job Summary: Plans, organizes, and performs scientific research projects in a particular scientific or academic field. Job Duties: Creates and conduct . . .
0.367
13137
Business Process Director
Job Summary: Directs the evaluation of existing business processes for the purposes of identifying and executing on improvement initiatives. Job Dutie . . .
612
Health Data Analysis Director
Job Summary: Directs and oversees a team that collects, manages, and analyzes clinical and/or claims related healthcare data with the goal of assessin . . .
0.49
11440
IT Database Architecture Manager
Job Summary: Manages multiple aspects relating to the design, modeling, testing, and implementation of high performing database architecture. Job Duti . . .
231
IT Database Architect III
Job Summary: Designs, constructs, and maintains relational databases for data warehousing. Job Duties: Develops data modeling and is responsible for d . . .
0.582
1847_2
Designer/Drafter--Mechanical I
Job Summary: Prepares design drawings to assist in developing ideas generated by engineers. Job Duties: Analyzes engineering drawings and related data . . .
1846_2
Designer/Drafter--Mechanical III
Job Summary: Prepares design drawings to assist in developing ideas generated by engineers. Job Duties: Analyzes engineering drawings and related data . . .
0.143
218
IT Data Warehouse Analyst II
Job Summary: Gathers and assesses business information needs and prepares system requirements. Job Duties: Performs analyses, development, and evaluat . . .
3314_2
IT Data Warehouse Specialist
Job Summary: Assists in developing and maintaining data warehouses. Job Duties: Completes a variety of tasks associated with designing and analyzing d . . .
0.582
11424
Product Marketing Analyst III
Job Summary: Assists in the development of marketing campaigns and strategies for assigned organizational products or product lines. Job Duties: Condu . . .
11425
Product Marketing Analyst IV
Job Summary: Assists in the development of marketing campaigns and strategies for assigned organizational products or product lines. Job Duties: Condu . . .
0.102
11112
Business Process Analyst II
Job Summary: Conducts evaluation of existing business processes for the purposes of identifying and executing on improvement initiatives. Job Duties: . . .
11841
Procurement Coordinator
Job Summary: Provides professional level support to the procurement function. Job Duties: Collects and provides initial analysis of data to be used by . . .
0.745
2031_2
Research Program Manager
Job Summary: Manages research programs concerned with supporting business development activities. Job Duties: Oversees data acquisition, data analysis . . .
564
Clinical Research Manager
Job Summary: Manages daily operations within the organization's clinical research programs. Job Duties: Responsible for the design and administration . . .
0.663
Looks like several good matches. One more preview of the descriptive statistics, and then I think we’re done.
Code
preview.describe()
match_confidence
count
367.00
mean
0.43
std
0.28
min
0.00
25%
0.17
50%
0.40
75%
0.66
max
1.00
Now with this file, we can pull in pay ranges for similar jobs with a quantified measure of the degree to which we have a match between surveys. Success.
Thanks for taking a look at this sample of how to perform job-matching in Python. Hope you find it useful.
Thanks to Josh Taylor for providing the basics of this method.